相信有自己訓練過模型的人都會遇到跟我一樣的問題,最後的曲線都會往上飄(這是參考李弘毅老師的投影片),那這是什麼原因造成的呢?在還沒弄懂之前,常常一直增加訓練資料,就算加到記憶體快爆了,好像結果也沒有改善。這道理就像得重感冒 一樣,吃藥或許有改善,但是最有用的還是打針最快了,所以就是要找對方法,對症下藥啦。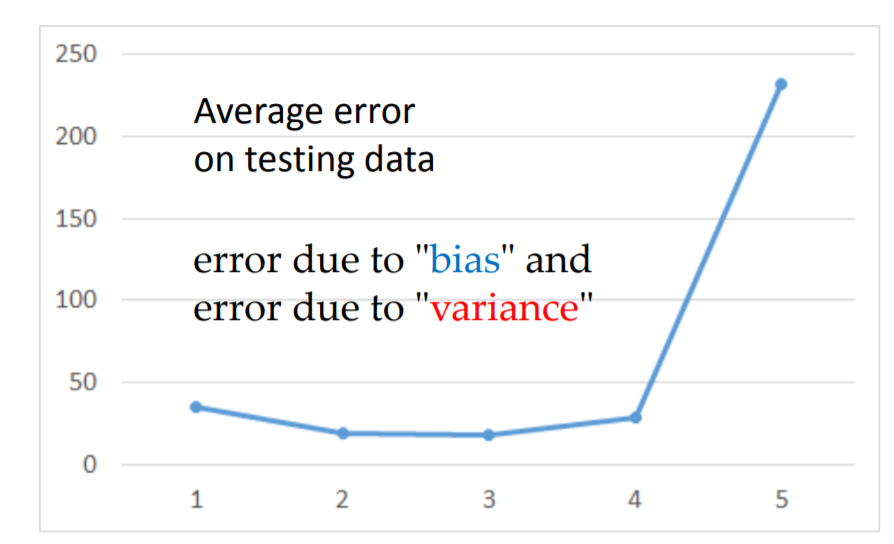
從下面這張圖可以看到,我們理想中的function是f^,給定一隻神奇寶貝的特徵值,可以得到理想上的output,這個function是我們不知道的,想起以前小時候玩game boy,神奇寶貝是非常熱門的,如果你知道這個function,就不用每次花很多時間訓練神奇寶貝,考慮要讓他吃什麼來增加親密度,什麼時候進化,如何提高cp值。
所以只能拿training data訓練出一個model,只能盡可能讓它跟理想中的越相近越好,但並不會完全一樣,我們把它叫做f*,從圖中可以明顯看到理想上跟實際上存在誤差,它是由bias與variance所造成的。
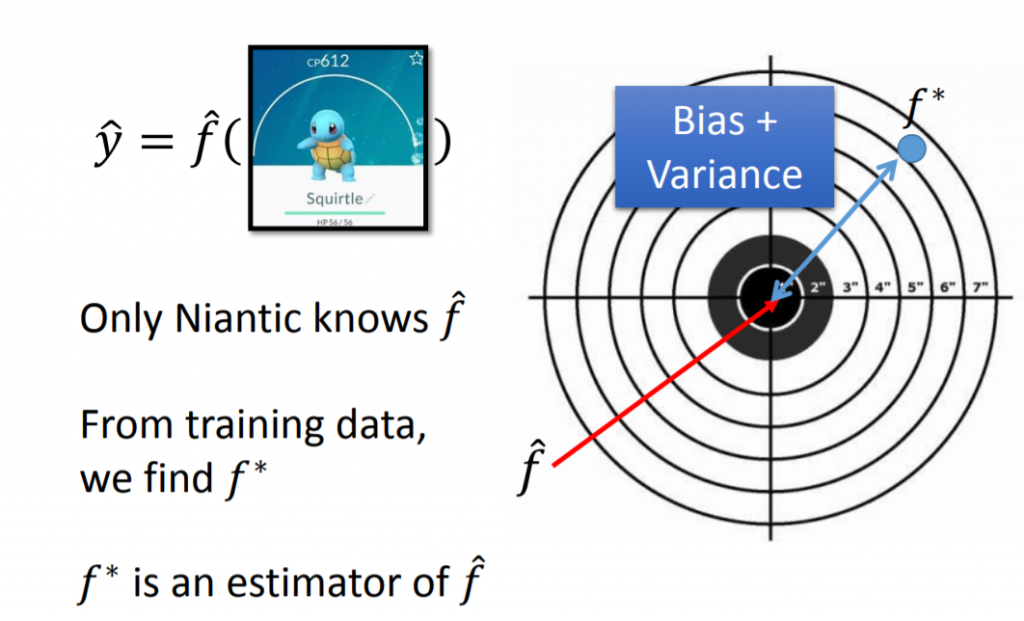
Bias and Variance
這邊我把bias與variance做個簡單的介紹:
Variance
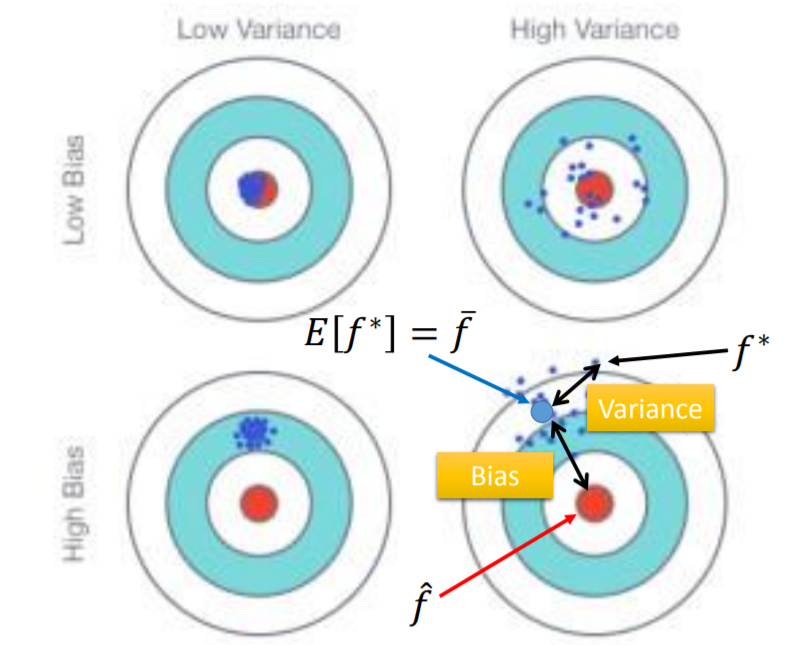
假設你在射飛鏢,你一開始已經瞄準某一個點,你如果力道太大,飛鏢很容易偏移,當你射很多次時,會發現它們都沒有集中在同一個點,可以對應到右邊的圖,當model越複雜,畫出來的直線越不集中;如果力道比較小,你可以慢慢調整手出去時的角度,減少偏移,所以當model越簡單,畫出來的直線越集中。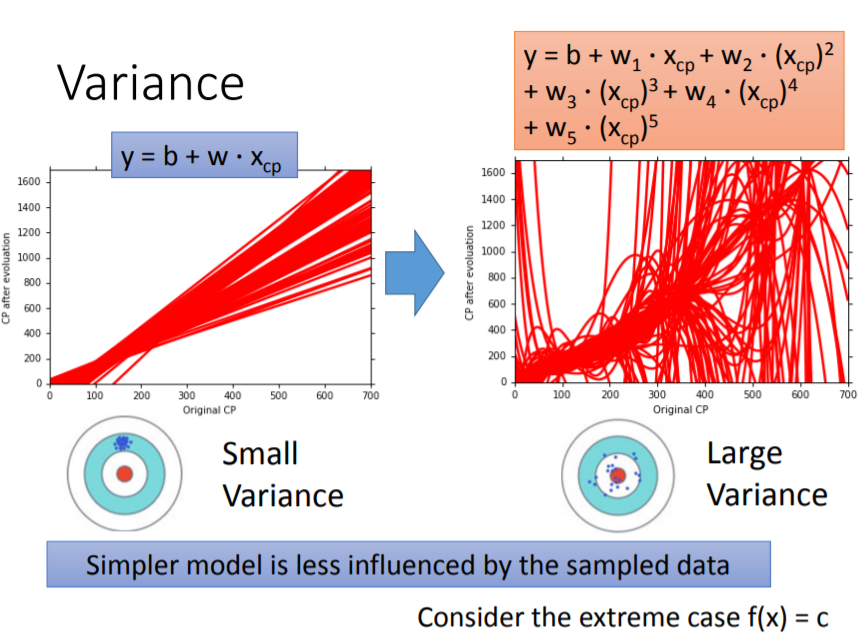
Bias
假設你在射飛鏢,你同樣小的力道,你射出去時比較不會偏移,但如果一開始就瞄錯地方,每次射出去都集中在某一處,但它們的平均卻離中心很遠,那就像左圖一樣;反之,右圖雖然每一次射出去都產生偏移,但卻離中心很近。
所以說,比較簡單的model它所包含的區域不包括target(中心),只能從這個範圍挑出最好的function,不管怎麼挑都挑不到最接近理想的那個function,因為一開始給的training data就有問題了;越複雜的model,它涵蓋了整個區域,但還是挑不到最好的function,因為給的training data不夠。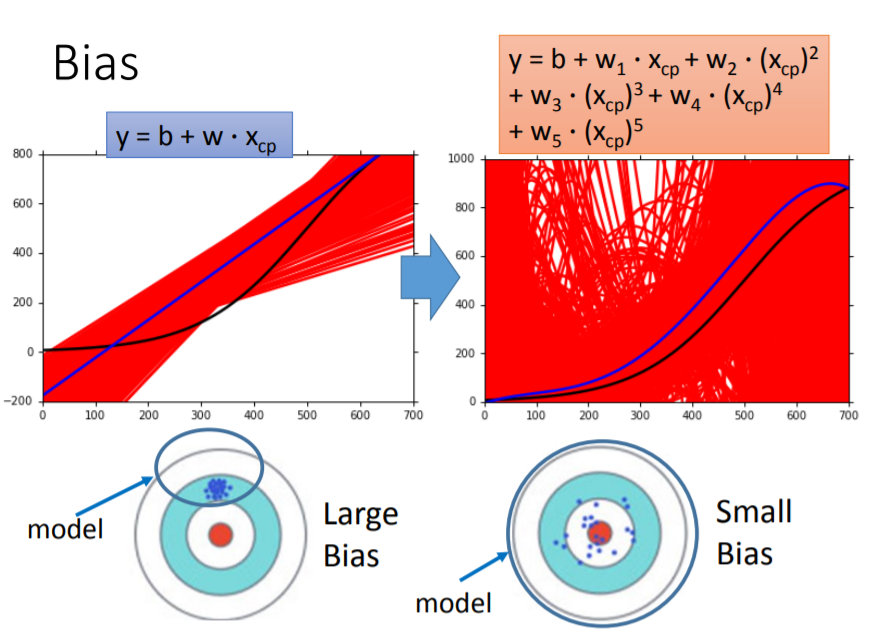
所以今天你訓練一個模型,如果有以下情形:
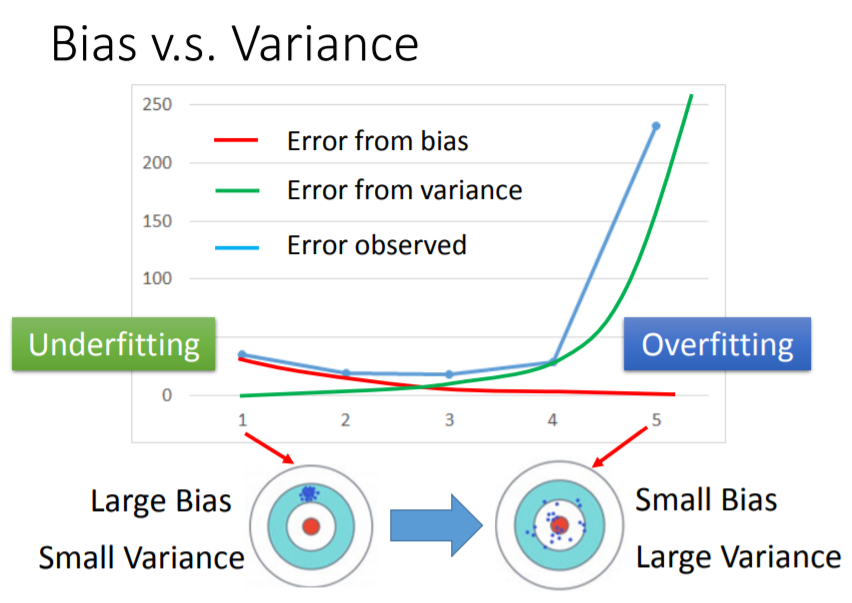
解決問題
如果你的model無法完全fit你的training data(如圖所示,紅色的線無法穿越每一個點),也就是underfitting,所以必須重新定義你的model,加入更多feature或是讓model更複雜,來fit所有的sample點。
如果,也variance太大,就是overfitting,所以必須增加訓練資料或是讓模型不要那麼複雜,但有時候資料並不適很好蒐集。所以還有一個方法,就是Regularization,它可以讓你的模型變簡單,由下圖可以看到,加入Regularization後,曲線變得越來越平滑。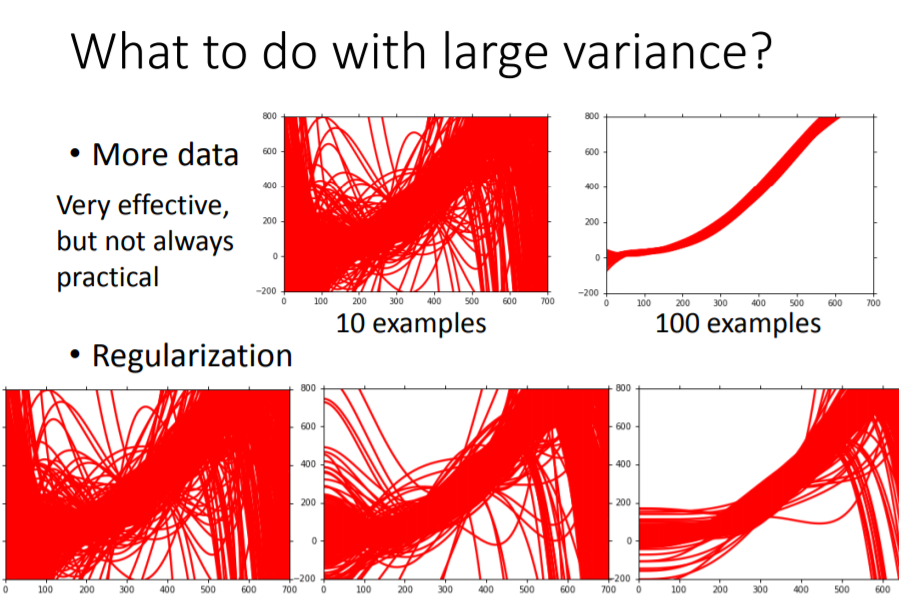


 iThome鐵人賽
iThome鐵人賽